afl-gcc find-as 用来寻找as 的路径。分别从环境变量AFL_PATH ,afl-gcc的路径(如果是绝对路径或相对路径调用afl-gcc) ,/usr/local/lib/afl三个地方寻找。如果找不到则报出相应错误。下列是我调试时打印出来的参数。
1 2 3 afl-gcc: find_as argv0: afl-gcc AFL_PATH: /usr/local/lib/afl
edit_params 用来对原生gcc 进行一个封装,加上了一些参数并存放到cc_params 中。如笔者使用afl-gcc -o test test.c 对文件进行编译,则会被封装成如下代码。
1 2 3 4 5 6 7 8 9 10 11 gcc -o test test.c -B /usr/local/lib/afl -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1
afl-as edit_params 对原生as 进行封装,参数存放到as_params 中。同时通过传入的参数设置一些变量的值,并且定义好modified_file 。原本传入的命令和经过修改的命令如下。
1 2 3 4 5 6 argv as_params /usr/local/lib/afl/as as --64 --64 -o -o /tmp/cc6ribB2.o /tmp/cc6ribB2.o /tmp/ccBeRi60.s /tmp/.afl-165297-1701960501.s
最终主函数中也会运行这个命令。
add_instrumentation 尝试把input_file 中的内容,进行插桩并放到modified_file 中。打开文件后满足以下规则进行插桩。
!pass_thru,不是用来传送数据
!skip_intel,不是intel汇编
!skip_app,不是__asm__内联汇编
!skip_csect,不与当前架构不适配(比如在x64架构中遇到x86汇编)
instr_ok,在text段中
instrument_next,有时会把instrument_next置零使得不会进行插桩
line[0] == ‘\t’,此行开头要为\t
isalpha(line[1]),line[1]要是字母
或者遇到跳转指令且不是jmp 时,也会插桩。
最后如果存在满足上述条件的地方,并进行了插桩,在最后则会根据架构插入main_payload_64或main_payload_32 。
总的来说就是遇到如下汇编时进行插桩。
1 2 3 function: —— 函数入口 .L0 —— GCC分支跳转标签 .jnz fun —— 条件跳转
trampoline 比如x64程序中插入的代码如下,会调用__afl_maybe_log,且rcx 的值是一个不超过1<<16 的随机数。
1 2 3 4 5 6 7 8 9 10 "leaq -(128+24)(%%rsp), %%rsp\n" "movq %%rdx, 0(%%rsp)\n" "movq %%rcx, 8(%%rsp)\n" "movq %%rax, 16(%%rsp)\n" "movq $0x%08x, %%rcx\n" "call __afl_maybe_log\n" "movq 16(%%rsp), %%rax\n" "movq 8(%%rsp), %%rcx\n" "movq 0(%%rsp), %%rdx\n" "leaq (128+24)(%%rsp), %%rsp\n"
__afl_maybe_log 检查共享内存(__afl_area_ptr)是否已经被设置,如果没被设置就调用__afl_setup进行初始化,设置过就调用__afl_store。
1 2 3 4 5 " movq __afl_area_ptr(%rip), %rdx\n" " testq %rdx, %rdx\n" " je __afl_setup\n" "\n" "__afl_store:\n"
__afl_setup 会检查__afl_setup_failure是否为0,也即检查之前__afl_setup是否调用失败,如果之前失败则跳转到__afl_return返回。否则再检查__afl_global_area_ptr是否为0,为0则跳转到__afl_setup_first进行初始化,否则把__afl_global_area_ptr赋值给__afl_area_ptr后,跳转到__afl_store。
1 2 3 4 5 6 7 " cmpb $0, __afl_setup_failure(%rip)\n" " jne __afl_return\n" " movq __afl_global_area_ptr(%rip), %rdx\n" " testq %rdx, %rdx\n" " je __afl_setup_first\n" " movq %rdx, __afl_area_ptr(%rip)\n" " jmp __afl_store\n"
__afl_setup_first 用来保存寄存器并保证栈对齐。之后调用shmat 获取共享内存地址存放到全局变量__afl_area_ptr及__afl_global_area_ptr中。执行完毕调用__afl_forkserver。
__afl_forkserver 向管道中写入4字节 ,来通知fuzz 我们fork-server 已经准备好。写入失败则会调用__afl_fork_resume。成功则调用__afl_fork_wait_loop。
1 2 3 4 5 6 7 8 9 10 " pushq %rdx\n" " pushq %rdx\n" " movq $4, %rdx /* length */\n" " leaq __afl_temp(%rip), %rsi /* data */\n" " movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */\n" CALL_L64("write") " cmpq $4, %rax\n" " jne __afl_fork_resume\n" "\n" "__afl_fork_wait_loop:\n"
__afl_fork_wait_loop 等待父进程从管道发送来的命令,并存放到__afl_temp中。读取失败则调用__afl_die,成功则调用fork 。子进程中调用__afl_fork_resume,当前进程把子进程号记录到__afl_fork_pid后,再写入管道,并且等待子进程返回。等待子进程执行完毕,把子进程状态写入管道告知fuzz 。再重新调用__afl_fork_wait_loop进行下一轮测试。
__afl_fork_resume 关闭管道描述符,恢复寄存器的值。调用__afl_store。
__afl_die 调用_exit 。
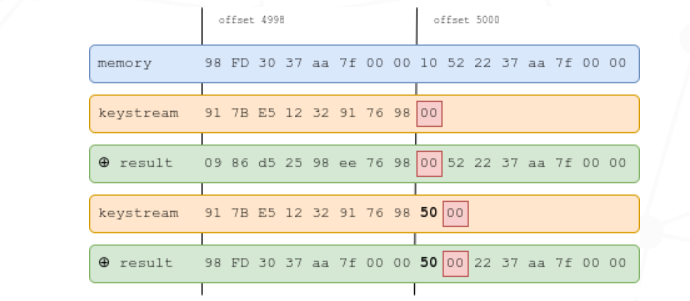
__afl_store 用来计算边的命中次数,RCX 即当前边的id。首先计算rcx和更新__afl_prev_loc 。
rcx = rcx ^ __afl_prev_loc
__afl_prev_loc = __afl_prev_loc ^ rcx
__afl_prev_loc = __afl_prev_loc >> 1
之后把__afl_area_ptr[rcx]+1
1 2 3 4 5 6 7 8 9 10 11 #ifndef COVERAGE_ONLY " xorq __afl_prev_loc(%rip), %rcx\n" " xorq %rcx, __afl_prev_loc(%rip)\n" " shrq $1, __afl_prev_loc(%rip)\n" #endif /* ^!COVERAGE_ONLY */ "\n" #ifdef SKIP_COUNTS " orb $1, (%rdx, %rcx, 1)\n" #else " incb (%rdx, %rcx, 1)\n" #endif /* ^SKIP_COUNTS */
afl-fuzz setup_signal_handlers 注册必要的信号处理函数
check_asan_opts 读取环境变量ASAN_OPTIONS 和MSAN_OPTIONS 并进行检查。
fix_up_sync 如果存在-M或-S,更改out_dir和sync_id。
save_cmdline 保存命令行参数到全局变量orig_cmdline 中。
fix_up_banner 获取测试文件名
check_if_tty 检查是否在tty 中运行,并记录在not_on_tty 里。
get_core_count 获取cpu的核心数
bind_to_free_cpu linux系统,如果存在空闲核心,就绑定到这个cpu上
check_crash_handling 检查crash的处理方式,执行echo core >/proc/sys/kernel/core_pattern ,以防存在延迟。
setup_post 如果存在环境变量AFL_POST_LIBRARY ,则会从其记录的动态链接库中获取函数afl_postprocess ,并记录到全局函数指针post_handler 中。这个函数指针会被common_fuzz_stuff 调用,用来处理out_buf 。
setup_shm 用来初始化共享内存,设置SHM_ENV_VAR ,和初始化virgin_bits ,virgin_tmout ,virgin_crash 。
如果in_bitmap 为空,就初始化virgin_bits ,virgin_tmout ,virgin_crash 为\xff 。
shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600); 分配共享内存,并把id存到shm_id 里。
atexit(remove_shm); 注册处理函数在退出时删除共享内存。(这个atexit也就是ctf里所谓的“exit-hook”的一种。😀
setenv(SHM_ENV_VAR, shm_str, 1); 如果不是dumb_mode ,设置SHM_ENV_VAR 为shm_str 。
trace_bits = shmat(shm_id, NULL, 0); 启动对共享内存的访问。
init_count_class16 初始化count_class_lookup16 ,目的是提高count_class_lookup8 的效率。先看一下count_class_lookup8 定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 static const u8 count_class_lookup8[256 ] = { [0 ] = 0 , [1 ] = 1 , [2 ] = 2 , [3 ] = 4 , [4 ... 7 ] = 8 , [8 ... 15 ] = 16 , [16 ... 31 ] = 32 , [32 ... 127 ] = 64 , [128 ... 255 ] = 128 };
count_class_lookup8 用来对路径命中率做规整。比如有些时候A->B ,出现了4次,有时候出现5次,这可能并不意味着出现新的路径。同时也为了减少因为命中次数不一样导致的区别。于是就定义了count_class_lookup8 用来做一个规整。把4-7 次都看作8 次,以此类推。
而AFL 中进行规整的时候一次性读入2字节,于是出现了count_class_lookup16。
setup_dirs_fds 创建输出文件夹以及记录fd。
read_testcases 从输入文件夹里读取所有文件,并将其加入测试队列中。
nl_cnt = scandir(in_dir, &nl, NULL, alphasort); 记录文件数量和信息
通过循环遍历所有文件
通过文件属性,大小和名称过滤掉无效文件
add_to_queue(fn, st.st_size, passed_det); 通过筛选,则加入测试队列
add_to_queue 增加测试样例到队列中。
新建一个queue_entry 结构体以记录test case 。
更新max_depth
如果queue_top 存在,则queue_top->next = q; queue_top = q;,否则 q_prev100 = queue = queue_top = q;
queued_paths 和pending_not_fuzzed 加1如果queued_paths % 100 = 0 ,则q_prev100->next_100 = q; q_prev100 = q;
设置last_path_time = get_cur_time();
load_auto 加载自动生成的提取出来的词典token。从目标文件中读取内容,如果满足要求则调用maybe_add_auto(tmp, len);
maybe_add_auto
遍历mem 里的字节,当出现有字节和第一个字节相同时停止遍历。
如果mem[0]==mem[1],则直接返回
如果mem 的长度为2 ,则将mem和interesting_16 进行比较,出现相同则直接返回
如果mem 的长度为4 ,则将mem和interesting_32 进行比较,出现相同则直接返回
将mem和extras中现有的数据 进行比较,如果出现与mem 相同的片段则直接退出。
设置auto_changed = 1;
遍历a_extras ,出现相同则a_extras[i].hit_cnt++;,否则把mem 加入a_extras
为in_dir 里的testcase在out_dir/queue 里创建hard link 。遍历输入目录的所有文件名,判断是否符合命名规范,如果不符合则按照规范重新命名,之后创建硬链接。
如果指定了extras_dir ,那么从extras_dir 里读取数据到extras 里,并按照大小排序。
find_timeout 没有指定timeout_given 时进入这个函数,设置timeout_given 。
detect_file_args 识别命令行参数中是否含有**@@,如果存在则替换为 out_dir/.cur_input**。
setup_stdio_file 如果没有指定out_file ,那么删除旧的并创建新的out_dir/.cur_input ,并获取其fd存放到out_fd 中。
check_binary 检查目标文件是否存在以及确保他不是一个shell script。并检查是否是完整的elf文件以及是否被插桩。
get_cur_time 毫秒级获取时间
执行测试用例,检查是否按照预期进行。
获取环境变量AFL_SKIP_CRASHES
遍历queue
打开q->fname,并读取其内容。
调用res = calibrate_case(argv, q, use_mem, 0, 1);
如果stop_soon==1,则直接返回。
如果res 为crash_mode或者FAULT_NOBITS,则打印提示。
根据错误类型抛出不同异常。
如果q->var_behavior 为真,说明该测试样例多次运行所覆盖的路径不同。
calibrate_case 测试输入样例是否会触发异常,以及检测新发现的路径样例的行为是否可变。
如果q->exec_cksum 为0,代表这个测试样例第一次运行,把first_run置为1。
保持原来的stage_cur、stage_max、stage_name。
如果测试样例不是来自queue,则use_tmout增大,且q->cal_failed++;。
设置stage_name = “calibration”;,并且通过fast_cal来判断,stage_max是3还是CAL_CYCLES(默认8),即这个样例测试的次数。
不是dumb mode,并且forkserver 没有启动,则调用**init_forkserver(argv);**。
如果不是第一次运行这个测试样例,则把trace_bits 拷贝进first_trace 。
开始calibrate stage
如果不是第一次运行,在第一轮calibrate stage结束时,显示界面,展示执行结果。
调用write_to_testcase(use_mem, q->len);,把测试内容记录到 out_file 中。
调用run_target(argv, use_tmout);执行测试样例,结果保存在 fault 中。
如果这是第一轮calibrate case,不是dumb mode,并且trace_bits没有记录到数据,则设置fault = FAULT_NOINST,跳转到abort_calibration。
通过hash32(trace_bits, MAP_SIZE, HASH_CONST);计算出 cksum 。
如果q->exec_cksum != cksum ,代表不是第一次运行,或者这个测试样例行为可变。
u8 hnb = has_new_bits(virgin_bits);
如果hnb > new_bits,则new_bits = hnb。
如果q->exec_cksum不为0,则代表不是第一次运行。
如果var_bytes为空,并且first_trace[i] != trace_bits[i],则设置var_bytes[i] = 1,stage_max = CAL_CYCLES_LONG。
var_detected = 1;
否则,代表是第一次运行。
设置q->exec_cksum = cksum;
拷贝trace_bits 进first_trace
计算时间和轮次,并计算一些信息
如果new_bits == 2 && !q->has_new_cov,则设置q->has_new_cov = 1,并且queued_with_cov++。
如果var_detected为1,则当前测试用例行为可变。调用mark_as_variable(q),并且queued_variable++。
恢复stage值。
如果不是第一次运行stage则调用show_stats,展示状态。
init_forkserver 初始化fork server 。
建立状态管道st_pipe 和控制管道ctl_pipe 。
fork出子进程
把FORKSRV_FD 重定向到ctl_pipe[0],把 FORKSRV_FD+1 重定向到**st_pipe[1]**。
关闭一些问价描述符。
调用execv(target_path, argv)。这里会执行我们之前插桩的程序,第一次执行时,会调用 __afl_fork_wait_loop ,以充当fork server 。
如果失败,则*(u32*)trace_bits = EXEC_FAIL_SIG。
父进程
关闭ctl_pipe[0]和st_pipe[1]。
等待fork server 启动。
能从**st_pipe[0]**读取到4字节即代表启动成功,超时则表示失败。
子进程异常处理
has_new_bits 用来检查是否出现新路径以及是否边的命中次数发生变化。
初始化current 为trace_bits ,virgin 为virgin_map ,ret=0。
8字节一组遍历trace_bits 。如果**(*(u32*)current)不为0,并且 (*(u32*)current & *(u32*)virgin)**不为0。则代表出现新的路径或者路径命中次数出现变化。
如果ret<2。
如果存在**(cur[i] && vir[i] == 0xff)**,那么设置ret=2,这代表出现新的路径。
*virgin &= ~*current;
如果ret存在,并且virgin_map == virgin_bits ,则设置bitmap_changed = 1
返回ret
count_bytes 统计非零字节数
每4字节一组遍历mem,u32* ptr = (u32*)mem,ret=0.
将ptr 与0xff,0xff00,0xff0000,0xff000000,分别相与,如果非零,则ret++。
返回ret,表示非零字节数。
run_target 用来fork出子进程进行fuzz测试。
首先清空trace_bits (记录路径的共享内存)。
如果是dumb mode或者no_forkserver非零。
fork出一个子进程,在关闭一系列文件描述符后,去执行**execv(target_path, argv)**。
否则正常通过fork server 来fork出一个进程进行fuzz。
通过fsrv_ctl_fd 写入4字节,来告诉fork server要开始fuzz。
再通过fsrv_st_fd 读取4字节,判断fork server是否成功fork出子进程。
AFL自己会等待fork出来的程序执行结束,并获取状态保存到status中。total_execs++。
调用classify_counts((u64*)trace_bits)。
根据status 的值,返回fuzz执行状态。
classify_counts(u64* mem) 用来对trace_bits 进行分类规整。
8字节一组遍历trace_bits 。
1 2 3 4 mem16[0 ] = count_class_lookup16[mem16[0 ]]; mem16[1 ] = count_class_lookup16[mem16[1 ]]; mem16[2 ] = count_class_lookup16[mem16[2 ]]; mem16[3 ] = count_class_lookup16[mem16[3 ]];
update_bitmap_score 当发现新的路径时,判断触发新的路径的样例是否更加favorable,favorable的意思是当前路径是否包含最小的路径集合来遍历到bitmap中的所有位。
fav_factor = q->exec_us * q->len。
遍历trace_bits,如果trace_bits[i]存在,则代表这里所指的路径已被覆盖。
如果fav_factor > top_rated[i]->exec_us * top_rated[i]->len,则代表原来的更优,直接continue,去判断下一条路径。
否则就说明这个新样例对于当前边更加favorable,–top_rated[i]->tc_ref,top_rated[i]->trace_mini = 0。
替换top_rated[i],top_rated[i] = q,并且q->tc_ref++。
如果q->trace_mini==0,则调用minimize_bits(q->trace_mini, trace_bits)。
score_changed = 1
minimize_bits 将描述边是否被覆盖到的以字节记录的trace_bits ,转化为以bit 记录的图。
cull_queue 用来精简队列
如果是dumb mode,或者score_changed==0,那么就直接返回。
设置score_changed=0,初始化temp_v[MAP_SIZE >> 3]为0xff。
遍历queue队列,使得q->favored = 0。
遍历top_rated 次。
如果top_rated[i]存在,并且temp_v[i >> 3] & (1 << (i & 7))存在。
从temp_v中清除掉top_rated[i]所有覆盖到的边。
top_rated[i]->favored = 1,queued_favored++。
如果top_rated[i]->was_fuzzed==0,则pending_favored++。
遍历队列queue,调用mark_as_redundant(q, !q->favored)。
mark_as_redundant 标记冗余队列。
如果state == q->fs_redundant,则直接返回。
设置q->fs_redundant = state。
构造路径fn=”out_dir/queue/.state/redundant_edges/q->fname”。
对state进行判断。
state存在,则说明该队列冗余,创建文件fn。
state为空,则删除文件。
show_init_stats 初始化之后,显示一些信息,以及设置一些值。
find_start_position 用来查询开始队列的位置。
如果resuming_fuzz==0,则直接退出。
否则就找到fuzzer_stats文件,打开并找到cur_path,并设置为ret。
如果ret >= queued_paths,则ret=0,返回ret。
write_stats_file 用来更新fuzzer_stats文件。
save_auto 用来自动保存生成的extras。
如果auto_changed==0,则直接退出。
打开”out_dir/queue/.state/auto_extras/auto_%06u”文件,并写入a_extras[i].data。
fuzz 主循环 fuzz的过程
fuzz_one 从queue中取出entry进行fuzz,成功返回0,否则返回1。
如果pending_favored 非0,并且当前queue已经被fuzz过,并且queue_cur->favored==0,则有99%的概率直接返回1。
如果pending_favored 为0,并且不是dumb mode,并且queue_cur->favored==0,queued_paths > 10。
如果queue_cycle > 1,并且queue没有被fuzz过,则有75%的概率直接返回1。
如果queue已经被fuzz过,则有95%的概率直接返回1。
打开测试样例文件,并且设置len = queue_cur->len,将文件映射到内存中,地址复制给orig_in,in_buf。
CALIBRATION阶段
如果queue_cur->cal_failed存在,并且queue_cur->cal_failed<3,则再次调用calibrate_case(argv, queue_cur, in_buf, queue_cycle - 1, 0)。
TRIMMING阶段
如果不是dumb mode,并且queue没有被修剪过,则调用**trim_case(argv, queue_cur, in_buf)**。
len = queue_cur->len,调用memcpy(out_buf, in_buf, len)。
PERFORMANCE SCORE 阶段
perf_score = calculate_score(queue_cur)。
如果skip_deterministic存在,或者queue已经被fuzz过,或者queue_cur->passed_det存在,则跳转去havoc_stage。
SIMPLE BITFLIP 阶段
bit翻转策略。
定义了如下宏,这个宏的作用是,翻转_ar的(_bf) >> 3偏移处字节的,第7-((_bf) & 7)比特。
1 2 3 4 5 #define FLIP_BIT(_ar, _b) do { \ u8* _arf = (u8*)(_ar); \ u32 _bf = (_b); \ _arf[(_bf) >> 3] ^= (128 >> ((_bf) & 7)); \ } while (0)
bitflip 1/1 阶段,逐步翻转每一个字节的每一比特,并且调用common_fuzz_stuff(argv, out_buf, len),之后会恢复这个比特。
并且如果在bitflip 1/1 阶段,连续翻转几个字节时,路径覆盖与原路径不一样,并且这几个新覆盖的路径一样,则AFL猜测这几个字节为token,并调用maybe_add_auto(a_collect, a_len)。
bitflip 2/1 阶段,连续翻转2bit。
bitflip 4/1 阶段,连续翻转4bit。
生成Effector map 。这个结构的作用是使得AFL对文件格式有一定的判断,从而提高效率。如果将某个字节完全反转,也不能导致路径发生变化,那么这个字节可能就是data ,对fuzz来说意义不大,在Effector map 中标记为0,表示该字节无效,在以后变异中跳过这些字节,以节省资源。
bitflip 8/8 阶段,以字节为单位进行翻转。在满足不是dumb mode和len >= 128的条件下,计算cksum,如果cksum != queue_cur->exec_cksum,那么标记eff_map[EFF_APOS(stage_cur)] = 1 ,即代表这个字节值得变异。
bitflip 16/8 阶段,以2字节为单位进行翻转,但是会跳过eff_map[EFF_APOS(stage_cur)]为0的字节。
bitflip 32/8 阶段,以2字节为单位进行翻转,同样会跳过eff_map[EFF_APOS(stage_cur)]为0的字节。
ARITHMETIC INC/DEC 阶段
byte加减法策略。
arith 8/8 阶段,每8个bit,进行加减运算。arith 16/8 阶段,每16个bit,进行加减运算。arith 32/8 阶段,每32个bit,进行加减运算。会跳过被eff_map认为无效的字段,以及跳过被变异过的测试样例。
INTERESTING VALUES 阶段
byte替换策略。
interest 8/8 ,每8个bit进行替换。interest 16/8 ,每16个bit进行替换。interest 32/8 ,每32个bit进行替换。会跳过被eff_map认为无效的字段,以及跳过被变异过的测试样例。
DICTIONARY STUFF 阶段
替换或插入tokens。
RANDOM HAVOC 阶段
dumb fuzz,完全随机的变异。
sync_fuzzers 读取其他fuzzer的测试样例,并进行测试,如果出现新路径,就保存到自己的queue文件夹里。
trim_case 修剪测试样例。
如果测试样例小于5,则直接返回。
计算len_p2,len_p2 = next_p2(q->len),remove_len=1/16 * len_p2 。
1 2 3 4 5 6 7 static u32 next_p2 (u32 val) { u32 ret = 1 ; while (val > ret) ret <<= 1 ; return ret; }
进入循环,循环跳出条件是remove_len< 1/1024 * len_p2。
跳过in_buf从remove_pos偏移处的trim_avail字节,写入到.cur_input中。
调用**fault = run_target(argv, exec_tmout)**,cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST)。
如果cksum == q->exec_cksum,就把原本测试样例中少去的这段给删除,实现了测试样例的简化。
否则remove_pos += remove_len。
show_stats()
如果needs_write存在,则删除原测试样例,将简化后的测试样例写到同名文件中。
返回fault。
calculate_score 根据速度,覆盖路径数,路径深度计算出一个得分,havoc变异阶段用。
common_fuzz_stuff 写测试样例进文件并进行测试。
如果post_handler 存在,则先执行out_buf = post_handler(out_buf, &len),对测试样例进行处理。
调用write_to_testcase(out_buf, len),写入.cur_input。
调用fault = run_target(argv, exec_tmout)。
如果fault == FAULT_TMOUT,返回1。
调用queued_discovered += save_if_interesting(argv, out_buf, len, fault)。
show_stats()。
返回0。
write_to_testcase 从mem写len到.cur_input中。
save_if_interesting 如果这个测试样例很有趣就保存下来,保存就返回1,否则返回0.
如果fault == crash_mode,但是没有出现新路径并且路径命中次数相同,则直接返回0.
调用add_to_queue(fn, len, 0),添加新测试样例到队列中。
调用queue_top->exec_cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST)。
调用calibrate_case(argv, queue_top, mem, queue_cycle - 1, 0)评估queue。
根据fault的值进行不同处理。
simplify_trace
参考链接 https://eternalsakura13.com/2020/08/23/afl/
https://www.z1r0.top/2023/03/23/AFL-fuzz%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/#simplify-trace
https://forum.butian.net/share/2092